Spatio-temporal Transcriptomics
Toy dataset from López-Lopera et al. (2019)
Data download: https://github.com/anfelopera/PhysicallyGPDrosophila
[56]:
import numpy as np
import torch
from torch.nn import Parameter
from matplotlib import pyplot as plt
from mpl_toolkits.axes_grid1 import ImageGrid
from pathlib import Path
from scipy.interpolate import interp1d
from torch.optim import Adam
from gpytorch.optim import NGD
from alfi.models import TrainMode, MultiOutputGP, PartialLFM, generate_multioutput_rbf_gp
from alfi.models.pdes import ReactionDiffusion
from alfi.utilities.data import dros_ground_truth
from alfi.utilities.fenics import interval_mesh
from alfi.datasets import DrosophilaSpatialTranscriptomics, HomogeneousReactionDiffusion
from alfi.trainers import PartialPreEstimator, PDETrainer
from alfi.plot import plot_spatiotemporal_data, Plotter1d
from alfi.utilities.torch import softplus, inv_softplus
from alfi.configuration import VariationalConfiguration
[33]:
drosophila = False
if drosophila:
gene = 'kr'
dataset = DrosophilaSpatialTranscriptomics(
gene=gene, data_dir='../../../data', scale=True, disc=20)
params = dict(lengthscale=10,
**dros_ground_truth(gene),
parameter_grad=False,
warm_epochs=-1,
natural=True,
zero_mean=True,
clamp=True)
disc = dataset.disc
else:
data = 'toy-spatial'
dataset = HomogeneousReactionDiffusion(data_dir='../../../data')
params = dict(lengthscale=0.2,
sensitivity=1,
decay=0.1,
diffusion=0.01,
warm_epochs=-1,
dp=0.025,
natural=True,
clamp=False)
disc = 1
data = next(iter(dataset))
tx, y_target = data
lengthscale = params['lengthscale']
zero_mean = params['zero_mean'] if 'zero_mean' in params else False
We can either create a simple unit interval mesh
[34]:
from dolfin import *
mesh = UnitIntervalMesh(40)
plot(mesh)
[34]:
[<matplotlib.lines.Line2D at 0x7f9ff01865d0>]

Alternatively, if our spatial data is not uniformly spaced, we can define a custom mesh as follows.
[35]:
# We calculate a mesh that contains all possible spatial locations in the dataset
spatial = np.unique(tx[1, :])
mesh = interval_mesh(spatial)
plot(mesh)
# The mesh coordinates should match up to the data:
print('Matching:', (spatial == mesh.coordinates().reshape(-1)).all())
Matching: True

Set up GP model
[36]:
# Define GP
if tx.shape[1] > 1000:
num_inducing = int(tx.shape[1] * 3/6)
else:
num_inducing = int(tx.shape[1] * 5/6)
use_lhs = True
if use_lhs:
print('tx', tx.shape)
from smt.sampling_methods import LHS
ts = tx[0, :].unique().sort()[0].numpy()
xs = tx[1, :].unique().sort()[0].numpy()
xlimits = np.array([[ts[0], ts[-1]],[xs[0], xs[-1]]])
sampling = LHS(xlimits=xlimits)
inducing_points = torch.tensor(sampling(num_inducing)).unsqueeze(0)
else:
inducing_points = torch.stack([
tx[0, torch.randperm(tx.shape[1])[:num_inducing]],
tx[1, torch.randperm(tx.shape[1])[:num_inducing]]
], dim=1).unsqueeze(0)
gp_kwargs = dict(learn_inducing_locations=False,
natural=params['natural'],
use_tril=True)
gp_model = generate_multioutput_rbf_gp(
1, inducing_points,
initial_lengthscale=lengthscale,
ard_dims=2,
zero_mean=zero_mean,
gp_kwargs=gp_kwargs)
gp_model.covar_module.lengthscale = lengthscale
# lengthscale_constraint=Interval(0.1, 0.3),
gp_model.double()
print(inducing_points.shape)
plt.figure(figsize=(2, 2))
plt.scatter(inducing_points[0,:,0], inducing_points[0, :, 1], s=1)
tx torch.Size([2, 1681])
torch.Size([1, 840, 2])
[36]:
<matplotlib.collections.PathCollection at 0x7fa001060c50>
Set up PDE (fenics module)
[37]:
# Define fenics model
ts = tx[0, :].unique().sort()[0].numpy()
t_range = (ts[0], ts[-1])
print(t_range)
time_steps = dataset.num_discretised
fenics_model = ReactionDiffusion(t_range, time_steps, mesh)
config = VariationalConfiguration(
initial_conditions=False,
num_samples=5
)
(0.0, 1.0)
[38]:
# Define LFM
parameter_grad = params['parameter_grad'] if 'parameter_grad' in params else True
sensitivity = Parameter(
inv_softplus(torch.tensor(params['sensitivity'])) * torch.ones((1, 1), dtype=torch.float64),
requires_grad=False)
decay = Parameter(
inv_softplus(torch.tensor(params['decay'])) * torch.ones((1, 1), dtype=torch.float64),
requires_grad=parameter_grad)
diffusion = Parameter(
inv_softplus(torch.tensor(params['diffusion'])) * torch.ones((1, 1), dtype=torch.float64),
requires_grad=parameter_grad)
fenics_params = [sensitivity, decay, diffusion]
train_ratio = 0.3
num_training = int(train_ratio * tx.shape[1])
lfm = PartialLFM(1, gp_model, fenics_model, fenics_params, config, num_training_points=num_training)
[39]:
if params['natural']:
variational_optimizer = NGD(lfm.variational_parameters(), num_data=num_training, lr=0.01)
parameter_optimizer = Adam(lfm.nonvariational_parameters(), lr=0.01)
optimizers = [variational_optimizer, parameter_optimizer]
else:
optimizers = [Adam(lfm.parameters(), lr=0.005)]
track_parameters = list(lfm.fenics_named_parameters.keys()) +\
list(map(lambda s: f'gp_model.{s}', dict(lfm.gp_model.named_hyperparameters()).keys()))
# As in Lopez-Lopera et al., we take 30% of data for training
train_mask = torch.zeros_like(tx[0, :])
train_mask[torch.randperm(tx.shape[1])[:int(train_ratio * tx.shape[1])]] = 1
orig_data = dataset.orig_data.squeeze().t()
trainer = PDETrainer(lfm, optimizers, dataset,
clamp=params['clamp'],
track_parameters=track_parameters,
train_mask=train_mask.bool(),
warm_variational=-1,
lf_target=orig_data)
tx = trainer.tx
num_t_orig = orig_data[:, 0].unique().shape[0]
num_x_orig = orig_data[:, 1].unique().shape[0]
num_t = tx[0, :].unique().shape[0]
num_x = tx[1, :].unique().shape[0]
ts = tx[0, :].unique().sort()[0].numpy()
xs = tx[1, :].unique().sort()[0].numpy()
extent = [ts[0], ts[-1], xs[0], xs[-1]]
x dp is set to tensor(0.0250, dtype=torch.float64)
Now let’s see some samples from the GP and corresponding LFM output
[40]:
time = orig_data[:, 0].unique()
latent = torch.tensor(orig_data[trainer.t_sorted, 2]).unsqueeze(0)
latent = latent.repeat(lfm.config.num_samples, 1, 1)
latent = latent.view(lfm.config.num_samples, 1, num_t_orig, num_x_orig)
time_interp = tx[0].unique()
time_interp[-1] -= 1e-5
latent = torch.from_numpy(interp1d(time, latent, axis=2)(time_interp))
# gp_model.covar_module.lengthscale = 0.3*0.3 * 2
out = gp_model(trainer.tx.transpose(0, 1))
sample = out.sample(torch.Size([lfm.config.num_samples])).permute(0, 2, 1)
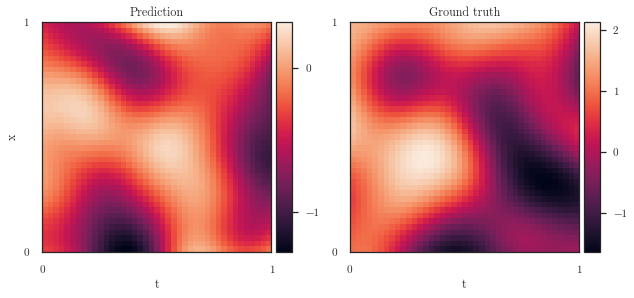
plot_spatiotemporal_data(
[
sample.mean(0)[0].detach().view(num_t, num_x).t(),
latent[0].squeeze().view(num_t, num_x).t(),
],
extent,
titles=['Prediction', 'Ground truth']
)
sample = sample.view(lfm.config.num_samples, 1, num_t, num_x)
output_pred = lfm.solve_pde(sample).mean(0)
output = lfm.solve_pde(latent).mean(0)
print(output.shape)
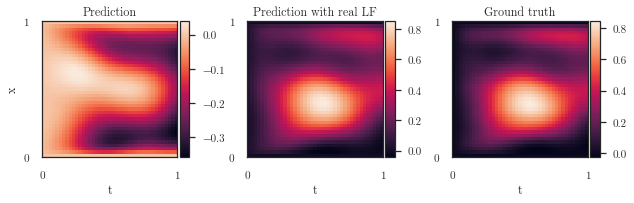
plot_spatiotemporal_data(
[
output_pred.squeeze().detach().t(),
output.squeeze().detach().t(),
trainer.y_target.view(num_t_orig, num_x_orig).t()
],
extent,
titles=['Prediction', 'Prediction with real LF', 'Ground truth']
)
/Users/jacob/miniconda3/envs/wishart/lib/python3.7/site-packages/ipykernel_launcher.py:2: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).
torch.Size([41, 41])
[40]:
<mpl_toolkits.axes_grid1.axes_grid.ImageGrid at 0x7fa02592f8d0>
[42]:
print(sensitivity.shape)
num_t = tx[0, :].unique().shape[0]
num_x = tx[1, :].unique().shape[0]
y_target = trainer.y_target[0]
y_matrix = y_target.view(num_t_orig, num_x_orig)
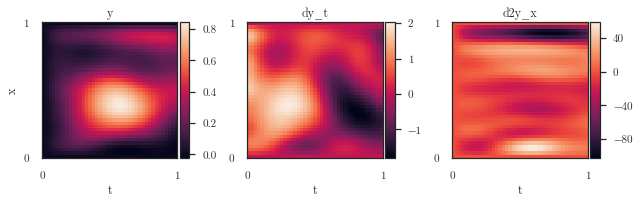
pde_func, pde_target = lfm.fenics_model.interpolated_gradient(tx, y_matrix, disc=disc, plot=True)
u = orig_data[trainer.t_sorted, 2].view(num_t_orig, num_x_orig)
u = u.view(1, -1)
print(u.shape)
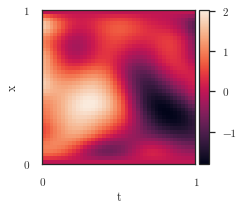
plot_spatiotemporal_data([pde_target.view(num_t, num_x).t()],
extent=extent, figsize=(3,3))
torch.Size([1, 1])
torch.Size([1, 1681])
[42]:
<mpl_toolkits.axes_grid1.axes_grid.ImageGrid at 0x7f9fef6fd2d0>
[43]:
train_ratio = 0.3
num_training = int(train_ratio * tx.shape[1])
print(num_training)
if params['natural']:
variational_optimizer = NGD(lfm.variational_parameters(), num_data=num_training, lr=0.04)
parameter_optimizer = Adam(lfm.nonvariational_parameters(), lr=0.03)
optimizers = [variational_optimizer, parameter_optimizer]
else:
optimizers = [Adam(lfm.parameters(), lr=0.09)]
pre_estimator = PartialPreEstimator(
lfm, optimizers, dataset, pde_func,
input_pair=(trainer.tx, trainer.y_target), target=pde_target,
train_mask=trainer.train_mask
)
504
[44]:
import time
t0 = time.time()
lfm.set_mode(TrainMode.GRADIENT_MATCH)
lfm.config.num_samples = 50
times = pre_estimator.train(60, report_interval=5)
lfm.config.num_samples = 5
Epoch 001/060 - Loss: 0.50 (0.50 0.00) kernel: [0.20550528 0.2055053 ]
Epoch 006/060 - Loss: 0.39 (0.39 0.01) kernel: [0.23078774 0.23129039]
Epoch 011/060 - Loss: 0.37 (0.36 0.01) kernel: [0.24667492 0.25505096]
Epoch 016/060 - Loss: 0.35 (0.34 0.01) kernel: [0.24611931 0.26790121]
Epoch 021/060 - Loss: 0.33 (0.32 0.02) kernel: [0.24697376 0.26993043]
Epoch 026/060 - Loss: 0.32 (0.30 0.02) kernel: [0.2521707 0.26915043]
Epoch 031/060 - Loss: 0.30 (0.28 0.02) kernel: [0.2529593 0.26371028]
Epoch 036/060 - Loss: 0.28 (0.26 0.02) kernel: [0.24880695 0.26215185]
Epoch 041/060 - Loss: 0.27 (0.24 0.03) kernel: [0.24748042 0.26141226]
Epoch 046/060 - Loss: 0.25 (0.22 0.03) kernel: [0.25038144 0.26232883]
Epoch 051/060 - Loss: 0.23 (0.20 0.03) kernel: [0.24515015 0.25645679]
Epoch 056/060 - Loss: 0.21 (0.18 0.03) kernel: [0.24506035 0.25134815]
[45]:
from alfi.utilities.torch import q2, cia
lfm.eval()
f = lfm(tx)
print(f.mean.shape)
f_mean = f.mean.detach()
f_var = f.variance.detach()
y_target = trainer.y_target[0]
print(f_mean.shape, y_target.shape, f_var.shape)
print('prot Q2', q2(y_target.squeeze(), f_mean.squeeze()))
print('prot CA', cia(y_target.squeeze(), f_mean.squeeze(), f_var.squeeze()))
gp = lfm.gp_model(tx.t())
lf_target = orig_data[trainer.t_sorted, 2]
f_mean = gp.mean.detach().view(num_t, num_x)[::disc].reshape(-1)
f_var = gp.variance.detach().view(num_t, num_x)[::disc].reshape(-1)
print('mrna Q2', q2(lf_target.squeeze(), f_mean.squeeze()))
print('mrna CA', cia(lf_target.squeeze(), f_mean.squeeze(), f_var.squeeze()))
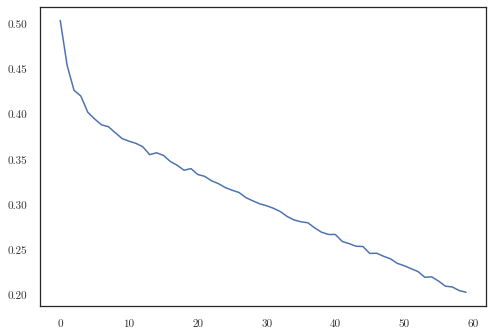
print(np.stack(times).shape)
plt.plot(np.stack(times)[:, 1])
torch.Size([1681, 1])
torch.Size([1681, 1]) torch.Size([1681]) torch.Size([1681, 1])
prot Q2 tensor(0.9555, dtype=torch.float64)
prot CA tensor(0.8239, dtype=torch.float64)
mrna Q2 tensor(0.8275, dtype=torch.float64)
mrna CA tensor(0.4753, dtype=torch.float64)
(60, 2)
[45]:
[<matplotlib.lines.Line2D at 0x7f9fffe806d0>]
[51]:
#print(hihi)
trainer.train(5)
Mean output variance: 0.006613638309770195
Test loss: 0.19012197007763404
prot Q2: 0.887
prot CA: 0.660
mrna Q2: 0.835
mrna CA: 0.484
Epoch 011/015 - Loss: 0.10 (0.07 0.04) kernel: [0.23642654 0.25396734] s: 0.9999999618701924 dec: 0.07482917543763193 diff: 0.003999277302588797
Mean output variance: 0.004143356411741863
Test loss: 0.17642557217076849
prot Q2: 0.896
prot CA: 0.532
mrna Q2: 0.838
mrna CA: 0.492
Epoch 012/015 - Loss: 0.10 (0.06 0.04) kernel: [0.23351392 0.25064798] s: 0.9999999618701924 dec: 0.07636863085455817 diff: 0.004084252710585124
Mean output variance: 0.0059391141198682825
Test loss: 0.16601622516039694
prot Q2: 0.948
prot CA: 0.797
mrna Q2: 0.839
mrna CA: 0.497
Epoch 013/015 - Loss: 0.09 (0.05 0.04) kernel: [0.23288824 0.24931108] s: 0.9999999618701924 dec: 0.0775412451893709 diff: 0.004177217326433502
Mean output variance: 0.004862229877781721
Test loss: 0.15790738446309927
prot Q2: 0.906
prot CA: 0.641
mrna Q2: 0.838
mrna CA: 0.500
Epoch 014/015 - Loss: 0.09 (0.05 0.04) kernel: [0.23276746 0.24843222] s: 0.9999999618701924 dec: 0.07860831372834004 diff: 0.004266474754910912
Mean output variance: 0.0021267050902141547
Test loss: 0.14142872501149154
prot Q2: 0.937
prot CA: 0.526
mrna Q2: 0.838
mrna CA: 0.500
Epoch 015/015 - Loss: 0.08 (0.04 0.04) kernel: [0.23344084 0.24730695] s: 0.9999999618701924 dec: 0.07936006891089503 diff: 0.004311524912559164
[51]:
[(1622796850.786326, 0.10212516102805735),
(1622796860.826846, 0.09633480689673313),
(1622796870.630483, 0.0921544071541819),
(1622796880.649955, 0.0886629607883353),
(1622796890.604911, 0.08188504166221224)]
[52]:
with torch.no_grad():
lfm.config.num_samples = 5
lfm.eval()
u = lfm.gp_model(trainer.tx.t()).sample(torch.Size([5])).permute(0, 2, 1)
u = u.view(*u.shape[:2], num_t, num_x)
dy_t_ = pde_func(
trainer.y_target,
u[:, :, ::disc].contiguous(),
sensitivity,
decay,
diffusion)[0]
out_predicted = lfm.solve_pde(u.view(5, 1, num_t, num_x)).mean(0)
ts = tx[0, :].unique().numpy()
xs = tx[1, :].unique().numpy()
extent = [ts[0], ts[-1], xs[0], xs[-1]]
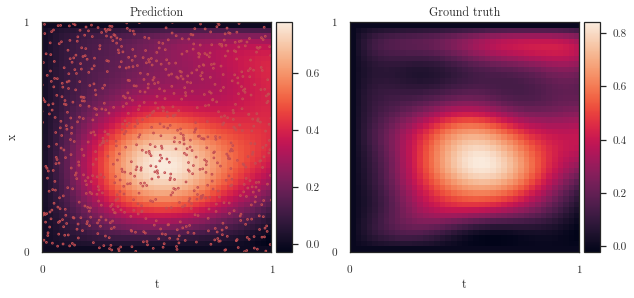
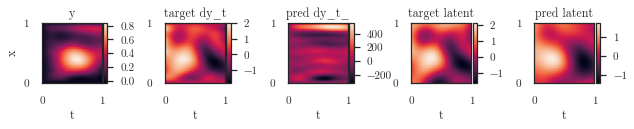
axes = plot_spatiotemporal_data(
[
trainer.y_target.view(num_t_orig, num_x_orig).t(),
pde_target.reshape(num_t_orig, num_x_orig).t(),
dy_t_.view(num_t_orig, num_x_orig).t(),
latent[0].view(num_t, num_x).t(),
u.mean(0).view(num_t, num_x).t(),
],
extent, titles=['y', 'target dy_t', 'pred dy_t_', 'target latent', 'pred latent']
)
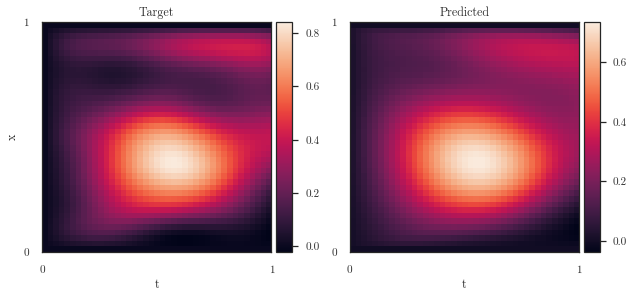
plot_spatiotemporal_data(
[
# real.t().detach(),
trainer.y_target.view(num_t_orig, num_x_orig).t(),
out_predicted.t().detach()
],
extent, titles=['Target', 'Predicted']
)
print([softplus(param).item() for param in lfm.fenics_parameters])
[0.9999999618701924, 0.07936006891089503, 0.004311524912559164]
[25]:
lfm = PartialLFM.load(filepath,
gp_cls=MultiOutputGP,
gp_args=[inducing_points, 1],
gp_kwargs=gp_kwargs,
lfm_args=[1, fenics_model, fenics_params, config])
# lfm = PartialLFM(gp_model, fenics_model, fenics_params, config)
gp_model = lfm.gp_model
optimizer = torch.optim.Adam(lfm.parameters(), lr=0.07)
trainer = PDETrainer(lfm, optimizer, dataset, track_parameters=list(lfm.fenics_named_parameters.keys()))
t_sorted, dp [53.925 60.175 66.425 72.675 78.925 85.175 91.425 97.675] 6.25
x dp is set to 1.0
t_sorted, dp [25.5 26.5 27.5 28.5 29.5 30.5 31.5 32.5 33.5 34.5 35.5 36.5 37.5 38.5
39.5 40.5 41.5 42.5 43.5 44.5 45.5 46.5 47.5 48.5 49.5 50.5 51.5 52.5
53.5 54.5 55.5 56.5 57.5 58.5 59.5 60.5 61.5 62.5 63.5 64.5 65.5 66.5
67.5 68.5 69.5 70.5 71.5 72.5 73.5 74.5 75.5 76.5 77.5 78.5 79.5 80.5
81.5 82.5 83.5 84.5 85.5 86.5 87.5 88.5] 1.0
[53]:
from alfi.utilities.torch import smse, cia, q2
num_t = tx[0, :].unique().shape[0]
num_x = tx[1, :].unique().shape[0]
# f_mean = lfm(tx).mean.detach()
# f_var = lfm(tx).variance.detach()
y_target = trainer.y_target[0]
ts = tx[0, :].unique().sort()[0].numpy()
xs = tx[1, :].unique().sort()[0].numpy()
t_diff = ts[-1] - ts[0]
x_diff = xs[-1] - xs[0]
extent = [ts[0], ts[-1], xs[0], xs[-1]]
print(y_target.shape, f_mean.squeeze().shape)
f_mean_test = f_mean.squeeze()
f_var_test = f_var.squeeze()
print(q2(y_target, f_mean.squeeze()))
print(cia(y_target, f_mean_test, f_var_test).item())
print(smse(y_target, f_mean_test).mean().item())
torch.Size([1681]) torch.Size([1681])
tensor(-11.9493, dtype=torch.float64)
0.33848899464604404
12.94156003961243
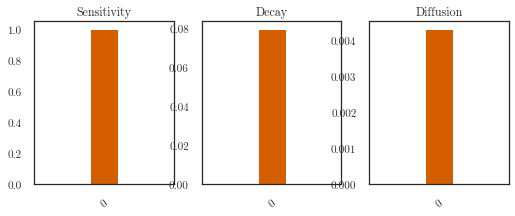
[60]:
plotter = Plotter1d(lfm, np.arange(1))
titles = ['Sensitivity', 'Decay', 'Diffusion']
kinetics = list()
for key in lfm.fenics_named_parameters.keys():
kinetics.append(softplus(trainer.parameter_trace[key][-1]).squeeze().numpy())
kinetics = np.array(kinetics).reshape(3, 1)
plotter.plot_double_bar(kinetics, titles=titles)
# plotter.plot_latents()
(3, 1)
[ ]: